
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 백준 1463
- 백준 boggle
- 42서울
- 백준 9202
- 백준
- 백준 트리
- 백준 1003
- 백준 1068
- 백준 1348
- C++
- 백준 낚시왕
- 백준 2217
- 백준 2585
- 백준 17143
- 백준 1로 만들기
- 42서울 라피신 후기
- 백준 로프
- 백준 주차장
- 백준 피보나치 함수
- 라피씬
- ACM Craft
- 백준 9095
- 라피신 후기
- 42서울 후기
- 피보나치 함수
- 백준 #백준4963 #섬의 개수
- BOGGLE
- 백준 경비행기
- 라피신
- 백준 1005
프로그래머의 개발노트
자료구조에 대한 기본적인 이해 본문
▶자료구조란?
프로그램이란 데이터를 표현하고, 그렇게 표현된 데이터를 처리하는 것입니다. 데이터의 표현이란 '데이터의 저장'을 포함하는 개념입니다. 이렇듯 '데이터의 저장'을 담당하는 것이 자료구조입니다.
예를 들면,
> int a = 10;
이 코드도 사실은 정수를 저장하기 위한 자료구조 입니다.
▶자료구조의 분류
선형구조 --- 리스트, 스택, 큐 | 비선형구조 --- 트리, 그래프
파일구조 --- 순차파일, 색인파일, 직접파일 | 단순구조 --- 정수, 실수, 문자, 문자열
*선형 자료구조 : 데이터를 선의 형태로 나란히 혹은 일렬로 저장하는 방식
*비선형 자료구조 : 데이터를 나란히 저장하지 않은 구조
▶자료구조와 알고리즘
자료구조가 '데이터의 표현 및 저장방법'을 뜻한다면, 알고리즘은 표현 및 저장된 데이터를 대상으로 하는 '문제의 해결 방법'을 뜻합니다.
> int arr[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
이렇게 배열이 선언된 것을 표현한 것을 자료구조적 측면의 코드라고 하고,
> for(int i = 0; i < 10; i++)
sum += arr[i]; // 변수 sum은 선언되어있다 가정
저장된 모든 합을 구하는 이 코드는 알고리즘적 측면의 코드라고 합니다.
이렇듯, 자료구조와 알고리즘은 밀접한 관계를 갖는다. 자료구조가 결정되어야 그에 따른 효율적인 알고리즘을 결정할 수 있기 때문입니다.
▶알고리즘의 성능분석 방법
알고리즘을 평가하는 요소에는 '시간 복잡도'와 '공간 복잡도'가 있습니다.
- 시간 복잡도(Time Complexity)
속도에 해당하는 알고리즘의 수행시간 분석결과를 가리켜 '시간 복잡도'라고 합니다. 시간 복잡도는 연산 횟수와 관련이 있습니다. 연산 횟수가 많을수록 시간 복잡도는 올라갑니다.
- 공간 복잡도(Space Complexity)
메모리 사용량에 대한 분석결과를 가리켜 '공간 복잡도'라고 합니다.
일반적으로 알고리즘을 평가할 때는 메모리의 사용량보다 실행속도에 초점을 둡니다. 다시 말하자면, 알고리즘을 평가하는 것은 시간 복잡도를 계산 하는것이 중요 포인트라고 할 수 있습니다.
시간 복잡도를 설명하기 위해 다음 코드를 보겠습니다.

시간 복잡도를 분석해서 데이터의 수 n에 대한 연산횟수의 함수 T(n)을 구해봅시다. 해당 알고리즘에서 사용된 연산자는 '<', '==', '++' 이렇게 세 개입니다. 이 코드에서 알 수 있는 사실은, LSearch 함수 안에서
> if (target == arr[i])
'==' 이 연산자의 사용을 줄인다면 '<' 와 '++' 연산자의 사용도 줄일 수 있습니다.
따라서 우리는 '==' 연산의 횟수를 대상으로 시간복잡도를 분석하면 됩니다.
만약, 운이 좋아서 우리가 찾고자 하는 target이 배열의 맨 앞에 존재한다면 비교연산('==')의 횟수는 1이 되겠고, 운이 좋지 않아 배열의 마지막에 있거나 아예 없다면 비교연산의 횟수는 n이 됩니다. 전자의 경우는 '최선의 경우(best case)'라고 하고, 후자의 경우는 '최악의 경우(worst case)'라고 합니다.
** 최선, 최악의 경우도 아닌 '평균적인 경우(average case)'도 있지만, 이 경우는 분석에 필요한 여러 가지 시나리오와 데이터를 현실적이고 합리적으로 구성해야 합니다. 즉 다양한 광범위하게 다양한 자료들이 수집되어야 하는데, 이는 쉬운일이 아닙니다. 이러한 이유로 일반적인 알고리즘의 평가에는 논란의 소지가 거의 없는 '최악의 경우(worst case)'가 선택될 수 밖에 없게 됩니다.
다음으로는 순차 탐색보다 좋은 성능을 보이는 이진 탐색 알고리즘을 보겠습니다.

이진탐색은 배열에 저장된 데이터가 이미 정렬된 상태여야 동작합니다.
First는 배열의 첫 인덱스이고, last는 배열의 마지막 인덱스 입니다. mid는 first와 last의 합을 2로 나눈것으로, 쉽게 말해서 first와 last의 중앙값입니다. 이 mid와 target을 비교하여 target이 arr[mid]보다 작으면 last는 mid -1 로 바꿔주고, 크면 first 를 mid + 1 로 바꿔주어 진행합니다.
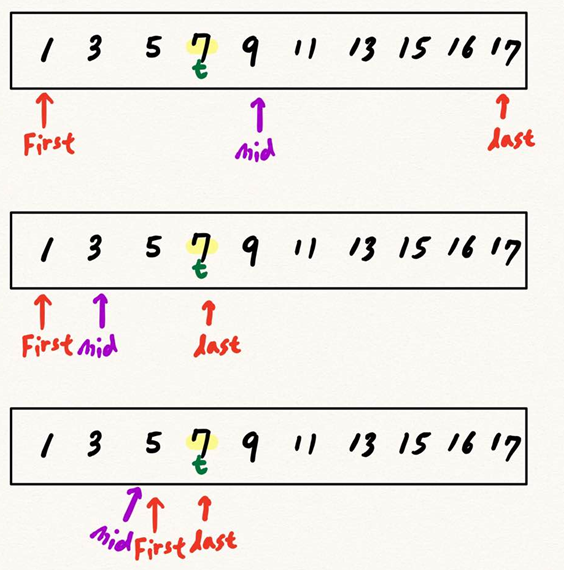

여기서 주목해야 할 점은, 첫 번째 arr[mid]와 target을 비교하고 last를 mid-1로 바꿔줌으로써 탐색의 대상이 절반으로 줄었다는 점입니다.
- 시간 복잡도
순차탐색으로 탐색을 할 경우 최악의 경우 n이었습니다. 이진탐색의 최악의 경우를 구해보겠습니다.
● 처음 데이터 수가 n일때 탐색과정에서 1회의 비교연산
● 데이터 수가 반으로 줄어 n/2일때 탐색과정에서 1회 비교연산
● 데이터 수가 반으로 줄어 n/4일때 탐색과정에서 1회 비교연산
...
이렇게 줄어서 1이 될 때까지 비교연산을 한번씩 진행하고, 마지막으로 n이 1일 때 비교연산을 한 번 더 진행하게 됩니다. n을 1이 될 때까지 2로 나눈 횟수를 k라고 하면, n과 k에 관한 식은 다음과 같습니다.
n * (1/2)^k = 1
이를 양변에 밑이 2인 로그를 취하게 되면, log2 n = k
***2는 로그의 밑이 2임을 나타냄
따라서 k는 log2 n 입니다.
최악의 경우에 대한 시간 복잡도 함수를 T(n)이라고 하면, T(n) = k + 1 이라는 식이 나오게 되는데, 위에서 구한 k를 대입하면 T(n) = log2 n 이 됩니다. 여기서 +1은 제외하게 되는데, 그 이유는 데이터의 수 n이 증가함에 따라서 비교연산의 횟수가 로그적으로 증가하는 것이기 더 중요하기 때문입니다. 연산횟수의 변화 정도를 판단하기 위해 T(n)이라는 식을 만들었기 때문에 성능분석에 있어서 +1은 중요하지 않으므로 제외시키게 됩니다.
▶빅-오 표기법
T(n)이 다항식으로 표현이 된 경우에 최고차항의 차수가 빅-오가 됩니다. n의 값이 엄청나게 커진다고 가정하면, 최고차항의 차수보다 낮은 차수의 값은 전체 값에 미미한 수준이기 때문입니다. 또한, 최고차항의 계수는 제외하게 됩니다. 빅-오는 데이터 수의 증가에 따른 연산횟수의 증가 형태를 나타내는 표기법이기 때문입니다.
빅-오 관점에서 다음 둘은 동일합니다.
"데이터의 수가 2, 3, 4개로 늘어날 때 연산횟수는 4, 8, 16으로 두 배씩 늘어났다."
"데이터의 수가 2, 3, 4개로 늘어날 때 연산횟수는 99, 198, 396으로 두 배씩 늘어났다."
또한 빅-오는 다음과 같이 생각할 수 있습니다.
"데이터 수의 증가에 따른 연산횟수 증가율의 상한선을 표현한 것"
참고문헌
- 윤성우의 열혈 자료구조

